Monitoring¶
About Skimmer¶
ITRS Log Analytics uses a monitoring module called Skimmer to monitor the performance of its hosts. Metrics and conditions of services are retrieved using the API.
The services that are supported are:
- Elasticsearch data node metric;
- Elasticsearch indexing rate value;
- Logstash;
- Kibana;
- Metricbeat;
- Pacemaker;
- Zabbix;
- Zookeeper;
- Kafka;
- Kafka consumers lag metric
- Httpbeat;
- Elastalert;
- Filebeat
and other.
Skimmer Installation¶
The RPM package skimmer-x86_64.rpm is delivered with the system installer in the “utils” directory:
cd $install_direcorty/utils
yum install skimmer-1.0.XX-x86_64.rpm -y
Skimmer service configuration¶
The Skimmer configuration is located in the /usr/share/skimmer/skimmer.conf file.
[Global] - applies to all modules
# path to log file
log_file = /var/log/skimmer/skimmer.log
# enable debug logging
# debug = true
[Main] - collect stats
main_enabled = true
# index name in elasticsearch
index_name = skimmer
index_freq = monthly
# type in elasticsearch index
index_type = _doc
# user and password to elasticsearch api
elasticsearch_auth = logserver:logserver
# available outputs
elasticsearch_address = 127.0.0.1:9200
# logstash_address = 127.0.0.1:6110
# retrieve from api
elasticsearch_api = 127.0.0.1:9200
logstash_api = 127.0.0.1:9600
# monitor kafka
# kafka_path = /usr/share/kafka/
# kafka_server_api = 127.0.0.1:9092
# comma separated kafka topics to be monitored, empty means all available topics
# kafka_monitored_topics = topic1,topic2
# comma separated kafka groups to be monitored, empty means all available groups (if kafka_outdated_version = false)
# kafka_monitored_groups = group1,group2
# switch to true if you use outdated version of kafka - before v.2.4.0
# kafka_outdated_version = false
# comma separated OS statistics selected from the list [zombie,vm,fs,swap,net,cpu]
os_stats = zombie,vm,fs,swap,net,cpu
# comma separated process names to print their pid
processes = /usr/sbin/sshd,/usr/sbin/rsyslogd
# comma separated systemd services to print their status
systemd_services = elasticsearch,logstash,alert,cerebro,kibana
# comma separated port numbers to print if address is in use
port_numbers = 9200,9300,9600,5514,5044,443,5601,5602
# path to directory containing files needed to be csv validated
# csv_path = /opt/skimmer/csv/
[PSexec] - run powershell script remotely (skimmer must be installed on Windows)
ps_enabled = false
# port used to establish connection
# ps_port = 10000
# how often (in seconds) to execute the script
# ps_exec_step = 60
# path to the script which will be sent and executed on remote end
# ps_path = /opt/skimmer/skimmer.ps1
# available outputs
# ps_logstash_address = 127.0.0.1:6111
In the Skimmer configuration file, set the credentials to communicate with Elasticsearch:
elasticsearch_auth = $user:$password
To monitor the Kafka process and the number of documents in the queues of topics, run Skimmer on the Kafka server and uncheck the following section:
#monitor kafka
kafka_path = /usr/share/kafka/
kafka_server_api = 127.0.0.1:9092
#comma separated kafka topics to be monitored, empty means all available topics
kafka_monitored_topics = topic1,topic2
#comma separated kafka groups to be monitored, empty means all available groups (if kafka_outdated_version = false)
kafka_monitored_groups = group1,group2
# switch to true if you use outdated version of kafka - before v.2.4.0
kafka_outdated_version = false
kafka_path- path to Kafka home directory (requirekafka-consumer-groups.sh);kafka_server_api- IP address and port for kafka server API (default: 127.0.0.1:9092);kafka_monitored_groups- comma separated list of Kafka consumer group, if you do not define this parameter, the command will be invoked with the--all-groupsparameter;kafka_outdated_version= true/false, if you use outdated version of kafka - before v.2.4.0 set:true
After the changes in the configuration file, restart the service.
systemctl restart skimmer
Skimmer GUI configuration¶
To view the collected data by the skimmer in the GUI, you need to add an index pattern.
Go to the “Management” -> “Index Patterns” tab and press the “Create Index Pattern” button. In the “Index Name” field, enter the formula skimmer- *, and select the “Next step” button. In the “Time Filter” field, select @timestamp and then press “Create index pattern”
In the “Discovery” tab, select the skimmer- * index from the list of indexes. A list of collected documents with statistics and statuses will be displayed.
Skimmer dashboard¶
To use dashboards and visualization of skimmer results, load dashboards delivered with the product:
curl -XPOST -ulogserver:<password> -H "osd-xsrf: true" -H "Content-Type: application/json" "https://127.0.0.1:5601/api/opensearch-dashboards/dashboards/import?force=true" -d@/usr/share/kibana/kibana_objects/skimmer_objects.json
The Skimmer dashboard includes the following monitoring parameters:
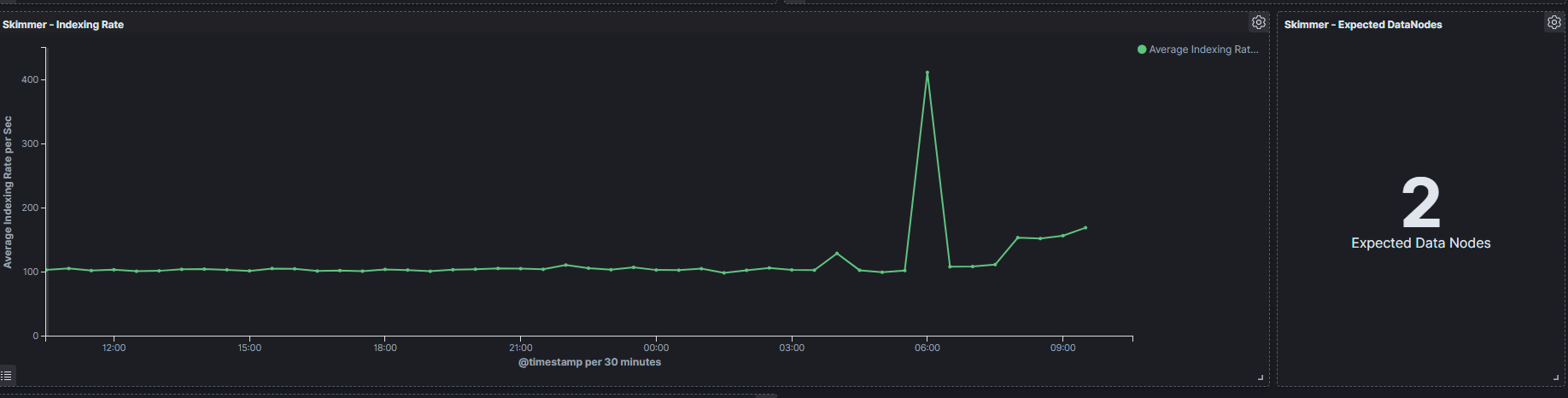
Elasticsearch - Heap usage in percent- is the total amount of Java heap memory that’s currently being used by the JVM Elasticsearch process in percentLogstash - Heap usage in percent- is the total amount of Java heap memory that’s currently being used by the JVM Logstash process in percentElasticsearch - Process CPU usage- is the amount of time for which a central processing unit was used for processing instructions of Elsticsearch process in percentElasticsearch - Node CPU usage- is the amount of time for which a central processing unit was used for processing instructions for specific node of Elasticsearch in percentElasticsearch - Current queries- is the current count of the search query to Elasticsearch indicesElasticsearch - Current search fetch- is the current count of the fetch phase for search query to Elasticsearch indicesGC Old collection- is the duration of Java Garbage Collector for Old collection in millisecondsGC Young collection- is the duration of Java Garbage Collector for Young collection in millisecondsFlush- is the duration of Elasticsearch Flushing process that permanently save the transaction log in the Lucene index (in milliseconds).Refresh- is the duration of Elasticsearch Refreshing process that prepares new data for searching (in milliseconds).Indexing- is the duration of Elasticsearch document Indexing process (in milliseconds)Merge- is the duration of Elasticsearch Merge process that periodically merged smaller segments into larger segments to keep the index size at bay (in milliseconds)Indexing Rate- an indicator that counts the number of saved documents in the Elasticsearch index in one second (event per second - EPS)Expected DataNodes- indicator of the number of data nodes that are required for the current loadFree Space- Total space and Free space in bytes on Elasticsearch cluster
Expected Data Nodes¶
Based on the collected data on the performance of the ITRS Log Analytics environment, the Skimmer automatically indicates the need to run additional data nodes.